
You researched the right websites, the right contacts, wrote an exciting e-mail and now you’re waiting for a story to pick up. This is the moment where a lot of us get anxious because the outcome is out of our control. Some journalists will get in touch right away, some will open your emails over and over and do nothing, and a some will publish a story days or weeks later. If the story isn’t picked up quickly, we start questioning if the campaign will fail.
Sometimes you can have a good story, but the timing is wrong. Have you ever wondered when journalists are likely to publish about a certain topic? Well, now you can have that answer.
Using a crawler and some easy XPath rules, you can scrape Google News and find out the specific dates those topics have hit the news in the past. When does the Christmas season start in the press? When is the new GoT season likely to become trendy? Keep reading to find out!
Guide and template for SERP scraping
We’ll show you how to run this using Screaming Frog, but I imagine other crawlers could do the same. The first step is to learn some XPath rules, which I learned from this guide published by BuiltVisible.
The goal is to scrape the top 100 (or more if you like) results for a certain topic and extract the date when these articles were published. This will give you a view for recurrent events (such as holidays) or even general behaviour towards a topic.
I very much recommend learning those rules because there’s much more you can do using XPath rules – but for the sake of this exercise, you just need to configure Screaming Frog with a few rules.
Spider Configuration:
- Untick all boxes from Basic Configuration
- JavaScript Rendering
User-Agent:
- Chrome
Mode:
- List
Configuration > Custom Extraction:
- XPath
- Add //h3, //div/span and choose “Extract Text”
- Add //h3/a and choose “Extract Inner HTML”
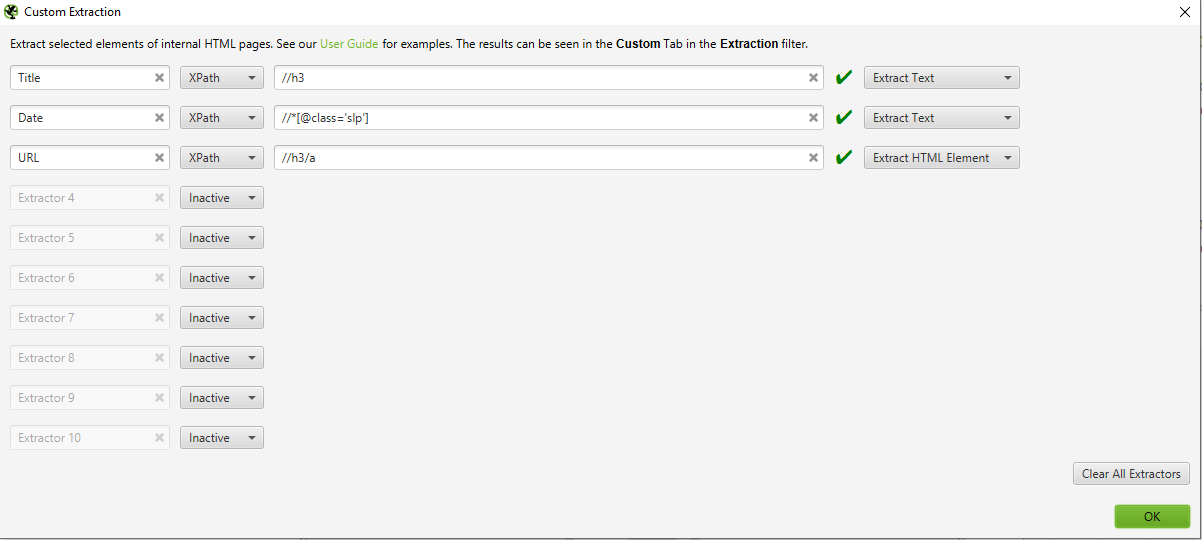
If you want to save the trouble on all of the above, here are the configured files for Google universal and Google News.
Now, we need to find the exact URL we want to scrape. This is where we I narrow down our target. Since I work for Wolfgang Digital and we’re an Irish agency, we picked St Paddy’s as a test.
The event happens every year in March, so I decided to filter anything available on Google News published between 1st February and 31st of March. You can filter the content directly on Google.
Usually shorter periods work better because you’re showing the 100 most important pieces of coverage on that particular topic and a larger selection of dates will just ignore many articles.
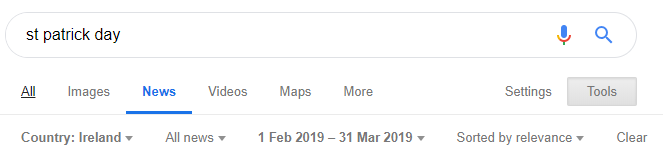
Once you have the URL, just add &num=100 at the end, so you can see the top 100 results in one page.
https://www.google.com/search?q=st+patrick%27s+day&rlz=1C1GCEU_enIE819IE819&biw=1920&bih=938&source=lnt&tbs=cdr%3A1%2Ccd_min%3A1%2F1%2F2019%2Ccd_max%3A3%2F31%2F2019&tbm=nws&num=100.
All configured? Then hit Start on Screaming Frog and go to the Custom tab (the very last one), where you’ll find the extracted data you just requested. The view is not great as all the data is in a horizontal line, so the best thing to do is to export to a csv file.

Making your data pretty
Once exported, organise your data for a better view. This blog post is focused on the publication date, but since you have the page title and URL, feel free to deep dive into what has been published on that topic. Have your target publications covered something along the lines of your campaign? Is there a pattern?
To clean up your results, there are a few handy Excel spreadsheet rules to use. This is the way I do it, but if you’re familiar with Excel or G-Sheets, feel free to ignore the below and do it your own way!
Date tab – Use “Text to Columns” and a “-” as a separator. This will split the publication name and date in two columns.
URL tab – select the whole column and replace “<a href=”/url?q=” for nothing. Then use “Text to Columns and a “&” as a separator.
This will give you a nice visualisation like the below:
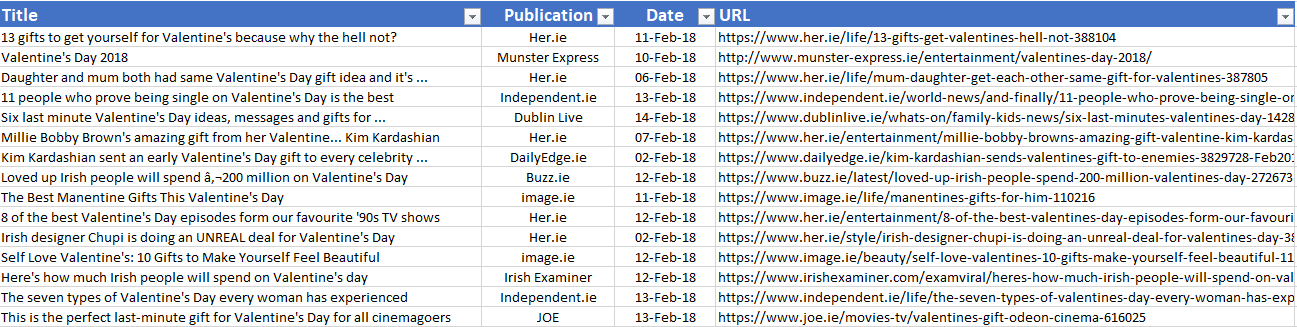
Almost there! Your final step is to make your data look good. If you have a huge list, let’s say 100 results, this raw list will still make it difficult to find out the specific dates when articles were published.
Simply select your dates in a separate column, remove duplicates and use a =COUNTIF formula to count the number of publications per day and put them on a chart to make visualisation much easier!
More examples
We took the first 100 results on Google News for a few topics and did the exercise above. Note that some results will be different depending on the time frame and location, so these may vary.
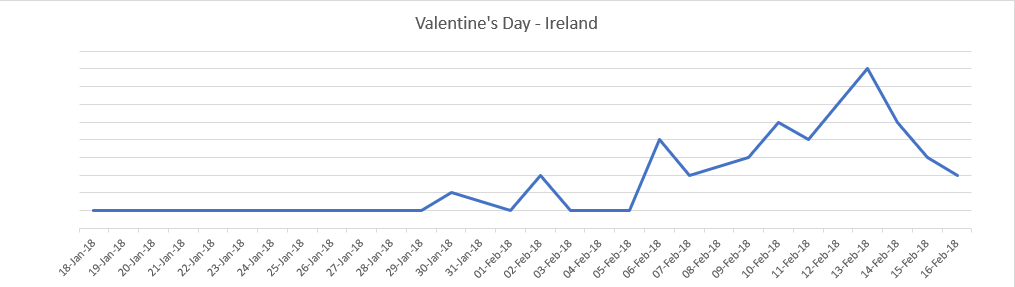
Valentine’s day
Location: Google News Ireland
Time frame: Jan 1 – Feb 18 2019
What we learned: the first week of February seems to be a good time to outreach. Stories started to pick up on the 6th and peaked on day before Valentine’s Friday (14th). Outreaching on the event day leaves you a smaller chance of getting coverage.
Game of Thrones
Location: Google News Ireland
Time frame: 3 to 17th July (2 weeks) and 18th July to 1st Aug (2 weeks)
What we learned: Two weeks before Game of Thrones 7th season was released, the press was already quite interested, so your campaigns can be out there quite early. After that, you will still find days with high coverage but the numbers can vary a lot.
Conclusion
Scraping the SERPS can give you good insights into a topic, what type of content is being published and a bit more confidence when reaching out. It’s always important to listen to your gut, but if you’re not familiar with a given topic, this can help you time your outreach perfectly.
Crafting strong linkable assets takes a lot of time and effort, so make sure you don’t reach out too early or too late and miss a huge opportunity!
Gus Pelogia
Teamwork@Pelogia
Gus Pelogia is a former journalist turned SEO, conference speaker, and once-in-a-while blogger. He is currently the SEO Lead at Teamwork, a project management SaaS used by companies like Netflix, PayPal, Disney, and more. Prior to this, Gus worked both in-house and at digital agencies in Argentina, Netherlands, and Ireland. He spent 5 years as an Account Manager and Team Lead at agencies such as Spark Foundry and Wolfgang Digital, working with clients from travel, e-commerce, and professional services, winning several industry awards.
Disclaimer: The author's views are entirely their own, and don't necessarily reflect the opinions of BuzzStream.
 Check out the BuzzStream Podcast
Check out the BuzzStream Podcast